目次
はじめに
このブログ記事は、Topcoder社が運営するブログの翻訳記事です。TC3株式会社はTopcoder社の日本で唯一のプレミア・パートナーであり、Topcoder社より許可を得て日本語に翻訳した記事を掲載しています。
今回は、Topcoderのクラウドソーシングモデルを活用するのに適したデータサイエンスプロジェクトや、Topcoderで一般的なデータサイエンスコンテストを行う際のプロセスについて紹介されたTopcoder公式ブログ記事の翻訳版をご紹介します。
英語での原文記事は”WHAT KIND OF DATA SCIENCE PROJECTS ARE A FIT FOR CROWDSOURCING?をご確認ください。
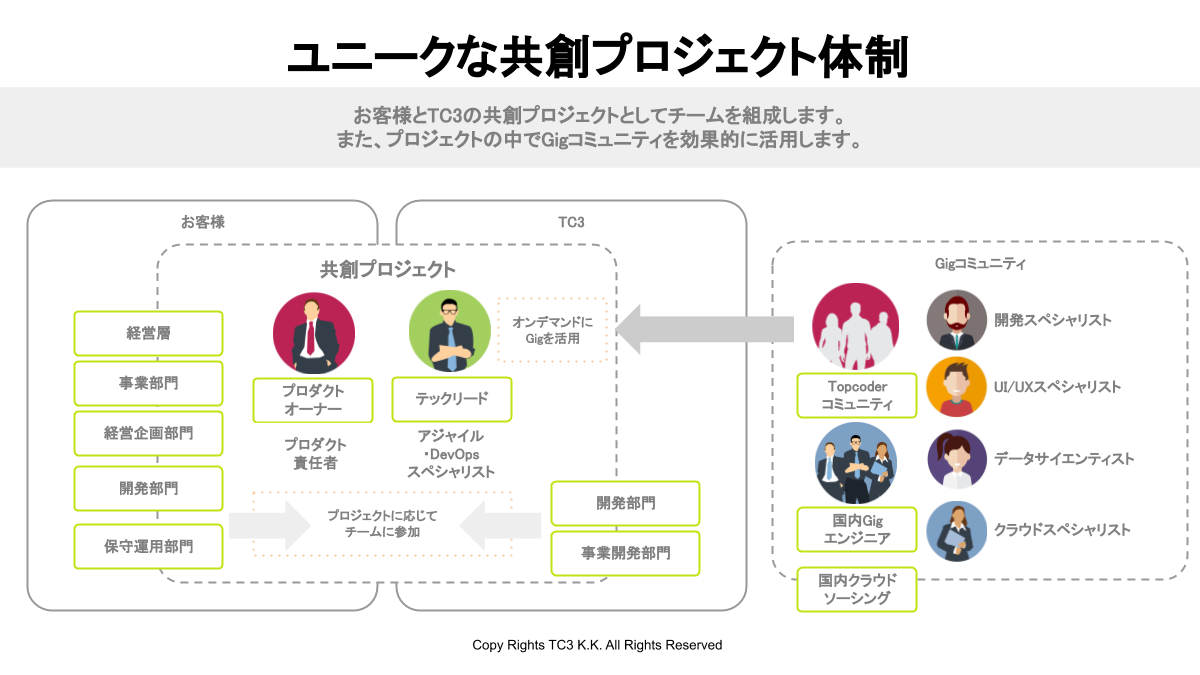
TC3では機械学習やAI・人工知能領域、組み合わせ問題、データ分析など様々な領域でTopcoderとの共創でお客様の課題解決をご支援しています。今回のブログ記事では海外での事例も含めて、Topcoderのコンテストに適切なプロジェクトの要素をご紹介しています。ぜひご参考ください。(なお、原文では文章のみでわかりにくいため、画像を含めてご説明いたします。)
今日、データサイエンティストといえば専門的で重宝される技術者です。しかし、あなたの企業が給与を支払ってデータサイエンティストチームを抱えるとなると大きなコストがかかります。そして、もしあなたの企業のデータサイエンティストチームが有能であったとしても、データサイエンスソリューションを必要とする問題やアルゴリズムは様々であり広い範囲に及ぶものです。クラウドソーシングは費用対効果が高く、データサイエンスプロジェクトを管理するのに効果的な方法で、いつでも最先端のスキルにアクセスして今あるチームを増強することができます。
ここからは、Topcoderを活用してデータサイエンスプロジェクトを実施するプロセスと、どのようなプロジェクトがクラウドソーシングに最適なのかを見ていきます。
コンテストの実施をベースとしたプロジェクトはあなたが最高の成果を得ることを意味します
Topcoderでは、コミュニティに所属するデザイナー、ディベロッパー、データサイエンティストがコンテスト要件に沿って競い合うことで、プロジェクトに適切なソリューションを提供します。競い合うことで、問題に対する多様なアプローチが生み出され、結果としてより質の高い結果が得られます。

自転車ロードレースのツール・ド・フランスをイメージしてください。スタート直後はサイクリストの大群から始まりますが、やがて先頭集団はほんの数名へと絞られていきます。それと同様に、データサイエンスコンテストにおいても、多くのメンバーが参加してきます。参加メンバーをCクラス、Bクラス、Aクラス、A+クラスのいずれかに分類した場合に、論理的には、Bクラス(good)の割合が最も高く、A+クラス(top experts)の割合が小さくなります。A+クラスは最も才能があるだけでなく、最も高価なリソースでもあります。これらの特に優れたドメインエキスパートに何度もアクセスする唯一の方法がTopcoderのクラウドソーシングモデルを活用することなのです。

コンテスト参加者のスキル僅差のイメージ
Topcoderのデータサイエンスコンテストのプロセス
Topcoderにおいて、一般的なデータサイエンスコンテストは5ステップのプロセスで構成され、それぞれのステージは次の通りです。
- プロジェクトのスコープを定義する
- コンテストとその要件を策定する
- コンテストの準備とTopcoderコミュニティへの告知を行う
- コンテストを開始しモニタする
- 成果物をテストし結果を分析する
Topcoderのデータサイエンスコンテストは、平均して75名のデータサイエンティストから500の成果物が提出され、その誰もが最高の結果を残すために競い合います。そしてその結果物の中で最も優れた成果物(一般的には複数の成果物)に対してのみ対価を支払うプロジェクト形式としています。つまりお客様は最良のソリューション(成果)に対してプロジェクト費用をお支払い頂くのであり、個人に対してや、その個人の稼働時間に対してではありません。
個々のフリーランサーのスキルを入念に吟味した上で採用する、もしくはエージェントに斡旋してもらうような従来の方法では選択肢は限定的であり、しかもあなたはそのフリーランサーを見つける事と、単一の成果物(それに満足できてもできなくても)の両方に対して費用を支払わねばなりません。また、そのプロジェクトから得られる成果は通常は想定の範囲内にとどまるものとなります。
クラウドソーシングに最適なデータサイエンスプロジェクトとは?
Topcoderのクラウドソーシングモデルは、特に以下の4つのデータサイエンスプロジェクトに適しています。
- 予測分析 – データを分析して将来のイベントや結果を正確に予測する。
- 目的最適化 – データサイエンティストが固有の制約や不確実性のなかで、特定の目的を最適化する。
- アルゴリズム最適化 – 既存のアルゴリズムを改善し、より高速かつ正確なアルゴリズムを開発する。
- 画像及びパターン認識 – パターン、相関、異常などを検出するために画像ライブラリやオーディオファイル等のデータ処理を実施する。
それではここでいくつかの例を紹介します。
がん検知技術 – 日本のテクノロジー企業であるコニカミノルタは現在(訳注:2017年時点)Topcoderと共に、全てのデジタル病理画像解析の基礎と位置付けられる、がん領域とその他の領域を見分けるがん認識技術の開発に取り組んでいます。Topcoderのデータサイエンティストのコミュニティにおいては、がん診断を支援するために病理画像のセグメンテーションを行う事を最終ゴールとしました。
GWAS分析 – 昨年TopcoderはPfizer社のビジネスハイパフォーマンスコンピュートグループ、Harvard大学クラウドイノベーションラボの協力者と共にGWAS分析のスピードアップを行う事に成功しました。クラウドソーシングを通して、PLINK 1.07(GWASの結果分析に使用したオープンソースソフトウェア)でのロジスティック回帰は591fold加速しました。
違法漁獲との戦い – この秋、私たちはNMIO (the National Maritime Intelligence-Integration Office:国家海事情報統合局) との画期的なプロジェクトを終えました。私たちは、世界中で違法・無規制・無報告で行われている漁獲を当局が見分け、撲滅する方策を開発するために、クラウドソーシングにおいて2つのパートでアルゴリズムコンテストを実施しました。
データサイエンスプロジェクトをクラウドソースする準備は出来ましたか? 始めるのは簡単です。
おわりに
いかがだったでしょうか。コンテスト形式のTopcoderを活用するのに適したデータサイエンスプロジェクトについてイメージできましたでしょうか?上記のような難題以外にもTC3/Topcoderでご支援できるような領域もございますので、ご興味ある方は一度お問い合わせください。