目次
はじめに
本記事はDeep Learning 論文 Advent Calendar 2022の20日目です。
こんにちは、@mumeco_mlです!(ぜひフォローしてください~😊)今回は自分が今年読んだ論文の中で一番衝撃的だった論文「MUSIQ:Multi-scale Image Quality Transformer」(arxiv)の紹介をしていきたいと思います。実はこの論文は2021年の8月にarxivに投稿されているので2022年のものではないのですが、あまりこの論文に関する記事もなかったので今回選ばせて頂きました!この記事が皆様の理解に少しでも役に立てれば幸いです!
一点申し訳ないのですが元々専門がRLとNLPで、あまりCVに詳しくないのでものすごい間違っている箇所等があるかもしれません。何かあればコメントやDM頂けると助かります🙇♂️
1文まとめ
どんな論文?
画像品質評価 (IQA: Image Quality Assessment) タスクにおいてSoTAを達成するTransformerベースのモデルMUSIQを提案したよ
何が凄いの?
任意の解像度/アスペクト比の画像をフルサイズのまま入力として扱うことが可能で、入力のリサイズが不必要なモデル構造がすごいよ
新規性はなに?
任意の解像度/アスペクト比に対応しマルチスケールな内部表現を得るためにMulti-scale Patch Embeddingというパッチ分割方法と、Hash-based 2D Spatial EmbeddingとScale Embeddingという2つのpositional embedding層を提案したよ
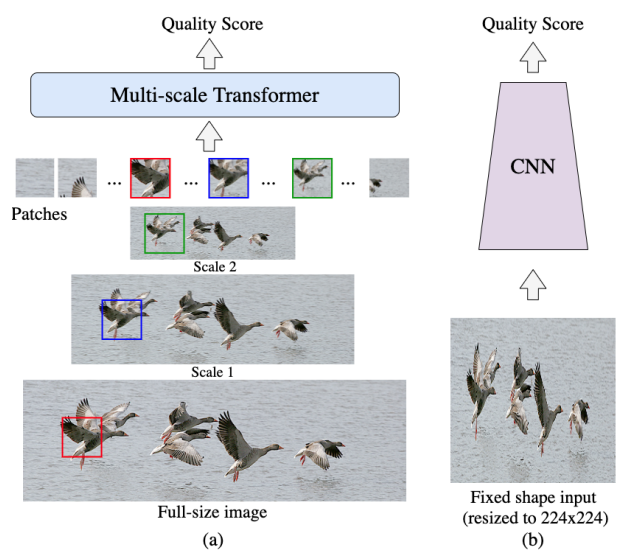
概要
画像品質評価 (IQA)
画像品質評価タスクとはその字のごとく画像の品質を定量的に評価するタスクです。評価データセットでは様々な画像に対して人手でスカラー値の評価を付与しています。IQAのデータセットの1つであるPaQ-2-PiQでは0から100の評価を約8000人の方が約4万枚の画像にしているとのことです。例えば、以下は車と飛行機の画像の比較で、車の画像はぶれてしまっているためGround-truth MOS(Mean Opinion Score)は17.9ですが、飛行機の画像は綺麗に取れているので82.1です。

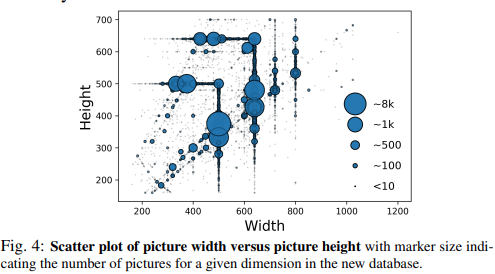
以下のグラフに示されるようにこのデータセットでは様々な解像度/アスペクト比の画像が含まれており、PaQ-2-PiQの論文では高い解像度かつ多様なアスペクト比の画像群での品質評価予測において高い性能を示すのは難しい、という課題感が述べられていました。
本論文の課題感としては以下の2点が挙げられています
- resizeやcropをしてしまうとIQAの品質評価値に対して大きく影響を与えてしまう
- 人間の視覚システムのようにmulti-scaleな特徴量を使用したい
今までの手法
このようなIQAタスクに対して、大きく3つの手法が提案されていたようです。
- Natural scene statisticsを使用した手法
- Code-bookを使用した手法
- CNNを使用した手法
中でもCNNを使用した手法がSoTAを達成していたようです。ただし、CNNの特徴として固定サイズの入力が求められるのでresizeやcropをしないといけない欠点がありました。この画像のresizeやcropは画像の品質に大きな影響を与えるため、特にIQAにおいてはresizeやcropが不必要であればその方が良いと筆者らは考えていたようです。ちなみにオリジナル画像をそのまま扱えるCNNの手法も提案されていたらしいです。欠点としてtraining batchのなかに単一の画像しか含められないため、大規模な学習においては非効率的とのこと。
オリジナル解像度でやりたいタスクは結構あるように思います。例えば、ちょっと古いのですがU-Netなんかは大きな解像度の画像を一度にresizeして入力するのではなく、分割(crop)して入力することでオリジナル解像度での入力をCNNで処理できるようにしています。
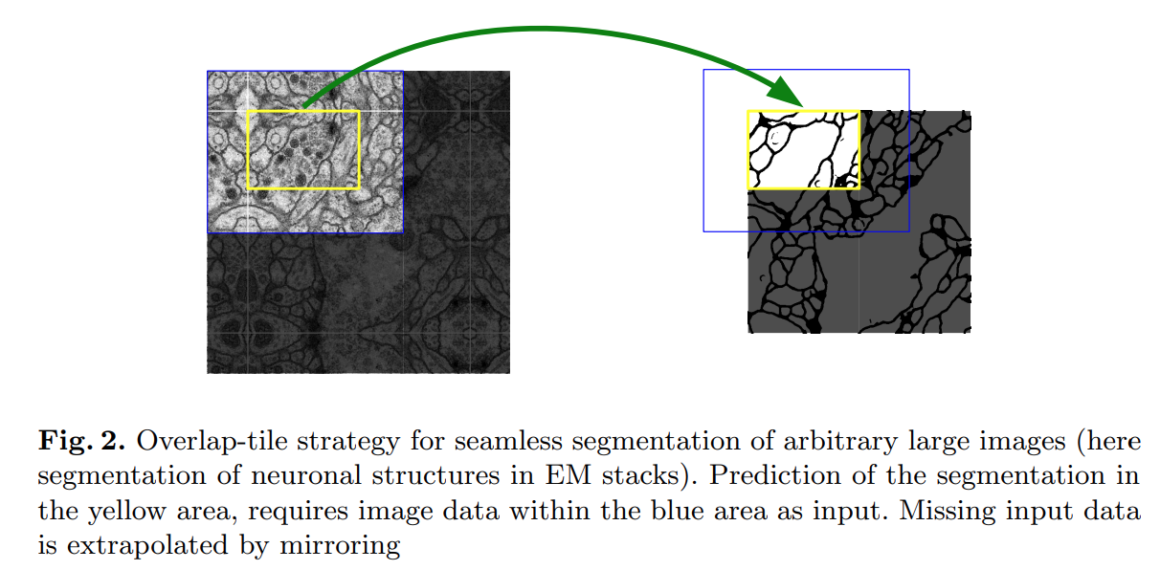
次に近年話題となったTransformer構造です。有名なVision Transformer(ViT)の仕組み上、理論的にはモデルが最終的に受け付けるのは小さなパッチですので、メモリが許す範囲で受け付けるパッチ数を増やしていけば高い解像度に対応できます。筆者らはこの性質からTransformer構造をIQAに応用することを思いついたそうです。理論上はパッチ数は可変とはいえバッチ学習をするためには基本的にはこれらは固定されます。例えばVision Transformerの論文では224×224の画像に対して16×16のパッチを複数作成する構造なので、高い解像度の画像は224×224へresizeする必要があります。
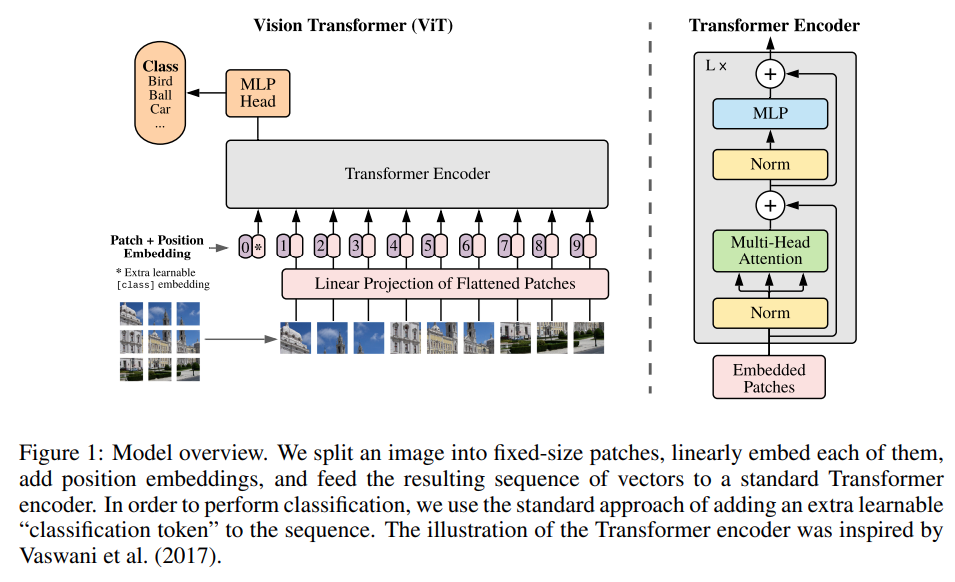
そして、Transformer構造に欠かせないPositional embeddingです。入力の順番の情報を付与する機構で、BERTではsin関数で決定的な値を生成したり、ViTでは学習可能なパラメータとして組み込まれていたりしますが、これらの手法は固定長の入力を想定しているため入力解像度が変化する状況では意味をなしません。また、様々な入力長に対応できるRelative positional embeddingsも提案されていますが、Transformer構造に大きな変更を加える必要があり、MUSIQではmulti-scaleな特徴量を作りたかったため採用しなかったそうです。
モデル構造
モデル構造はとてもシンプルです。MUSIQが解決したいことは以下の2点で
- multi-resolution かつ multi-aspect-ratioな画像をオリジナル解像度で受け付けること
- multi-scaleな画像の特徴量を得ること
Transformer構造のうちEmbeddingにのみ変更を加えます。つまり様々なTransformer構造に適用することが可能なのです!論文ではViTの構造を使っているそうです。
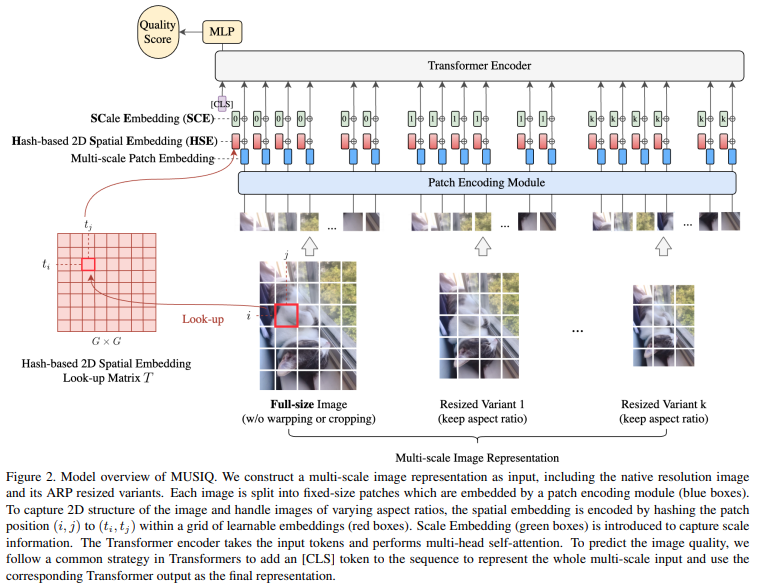
Multi-scale Patch Embedding
MUSIQではmulti-scaleな画像の特徴量を扱います。これは、IQAでは局所的な特徴と大域的な特徴のどちらにも影響されるためです。まず、オリジナル解像度の画像をパッチ分割して入力することを考えると、各パッチは画像の局所的な特徴を表すことになります。では、大域的な特徴を得るにはどうすればいいのでしょうか。Transformer構造では入力のパッチ自体は固定長になってしまうためパッチサイズを変えることはできません。MUSIQではこの問題を画像自体のresizeによって解決しています。つまり、オリジナル解像度をパッチ分割して入力し、同時にresizeして小さくした画像もパッチ分割して入力することで、multi-scaleな特徴量の獲得を可能にしています。このresizeはアスペクト比は維持したものとなっており、以下の数式に従い実施されます。
まず、resizeされた長辺の長さ\(L_{k}\)を事前に定義します。\(k\)はresize回数です。オリジナル解像度の高さを\(H\)、幅を\(W\)とすると以下のように、\(k\)回resizeされた画像の高さ\(h_{k}\)と幅\(w_{k}\)は次のように計算されます。
$$
a_{k} = L_{k}/\max(H,W),\quad h_{k}=\alpha_{k}H,\quad w_{k}=\alpha_{k}W
$$
つまり、画像の長辺を事前に決定した値に揃えるようにresizeするということですね。
次にパッチ分割について説明します。パッチは長さ\(P\)の正方形パッチです。入力画像の解像度は必ずしも\(P\)の倍数とは限らないので、その場合はゼロパディングをします。パッチ分割された後は、Patch Encoding Moduleで次元数\(D\)の内部表現に変換されます。ViTではこのパッチから内部表現へ線形変換を用いていましたが、MUSIQでは5層のResNetを重み共有させて各パッチに適用させています。これはImageNetでの事前学習実験において、線形変換よりも浅い層のResNetの方が性能が良かったからとのことです。オリジナル画像に対するパッチ数\(N\)とresize画像に対するパッチ数\(n_k\)は次のように計算されます。
$$
N=HW/P^2 \quad and \quad n_k = h_k w_k /P^2
$$
つまり、総パッチ数は \(N_{all} = N + \sum_{k=1}^{K} n_k\) ということですね。そして、様々な入力を受け付けるということは \(N_{all}\) は解像度やアスペクト比によって変化するということです。モデル構造としては固定のパッチ数を設定したいので、NLPでよく使われるゼロパディングをします。つまり、モデル構造として大きめのパッチ数を設定し、足りないパッチ数分を0で埋めたパッチで補うことをします。実際にこれらのゼロパディングされたパッチはattention maskを使うことでself-attentionにおいて無視されるので性能には影響を及ぼしません。
長辺を事前に設定した値へresizeするため、resizeされた画像に関するパッチ数は正確に見積もることが可能で \(n_k \leq L_k^2/P^2=m_k\) となります。一方で、オリジナル解像度は生成されるパッチ数が物凄い数になる可能性もあります。論文ではパッチ数の上限 \(l\) を設定し、パッチ数がこれに足りなければpadし、多すぎるならcutしているそうです。ただし、この処理はパッチ数の上限を揃えることで効率的に学習するための処理であるので、1枚ずつ処理してもよい推論時はself-attentionのメモリ使用量が許す範囲で任意のパッチ数上限を設定することが可能です。
Hash-based 2D Spatial Embedding
MUSIQでは以下の3点を解決するPositional enbedding層のHash-based 2D Spatial Embedding (HSE)を提案しています。
- 任意の解像度かつアスペクト比の画像に対して効率的にパッチ情報をエンコードできること
- 異なるスケールで空間的に近いパッチは近い埋め込みを持つことができること
- 効率的かつ簡単に実装できTransformerのAttentionに影響を及ぼさないこと
このHSEの実装は本当にシンプルです。まず学習可能な \(G\times G\) のパラメータ行列 \(T=\mathbb{R}^{G \times G \times D}\) を用意します。そしてこの \(T\) の要素を各パッチに足してあげます。この時どの要素 \((t_i,t_j)\) を足してあげるかという点ですが、以下の方法で計算します
$$
t_i = \frac{i \times G}{H/P}, \quad t_j = \frac{j\times G}{W/P}
$$
つまり、パッチ分割の行、列の番号によってHSEの特定の要素を指定してそれを足してあげるということですね。ちなみに、上記の式は割り切れないことが多いと思いますが、単純に近い整数へ丸めているそうです。確かにこの方法だと超簡単に実装が出来て、attentionに影響を及ぼさないし、異なるスケールの画像に対して同じ箇所は同じようなpositional enbeddingを与えることが可能です。アイデアの勝利!
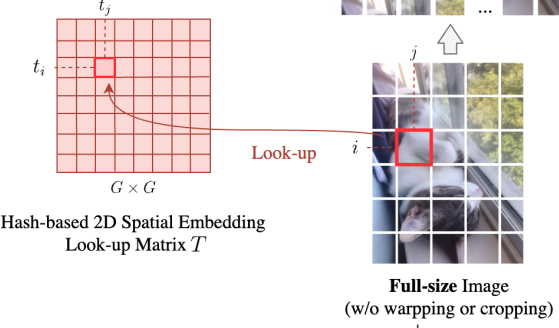
ちなみにグリッドサイズ\(G\)はハイパーパラメータで、小さすぎるとパッチ間で同じようなpositional enbeddingとなってしまい、大きすぎるとメモリをより消費するため十分なデータがないと性能が発揮できない可能性があるとのことです。実験では \(G=10\) としています。
Scale Embedding
上記のHSEではパッチの場所自体の情報を付与しているが、resizeに関する情報が付与されていませんでした。Scale Embeddingではresizeに関する情報を付与します。こちらもかなりシンプルで、学習可能なパラメータ \(Q \in \mathbb{R}^{(K+1) \times D}\) を用意します。 \(K\) はresizeする最大数です。そして、各パッチに関してそのresize回数に応じた \(Q_k \in \mathbb{R}^D\) を足してあげます。つまり \(Q = [Q_0, Q_1, …, Q_k]\) ということです。
Pre-trainingとFine-tuning
TransformerモデルはImageNet等を用いた事前学習が必要ですが、MUSIQでも事前学習を行っています。特徴的なのは、data augumentation時にcropは実施するのですが、resizeはせずに様々なアスペクト比の入力をしたそうです。IQAタスクでのfine-tuningではresizeやcropは全くせずにMUSIQへ入力し、augumentationにはrandom horizontal flippingのみを使用したそうです。
評価実験
実装の詳細
以下にざっとMUSIQのパラメータを列挙します
- リサイズ回数は2回まで(つまりオリジナル、リサイズ1、リサイズ2)
- リサイズ1の長辺サイズは384、リサイズ2の長辺サイズは224
- パッチサイズ\(P\)は32
- 入力パッチ数\(l\)は512
- 内部表現の次元数\(D\)は384
- グリッドサイズ\(G\)は10
- モデルのパラメータ数は2700万
実験結果
全部で4つのデータセットでそれぞれSoTAとのことでした。ここではPqQ-2-PiQの結果だけ載せておきます。
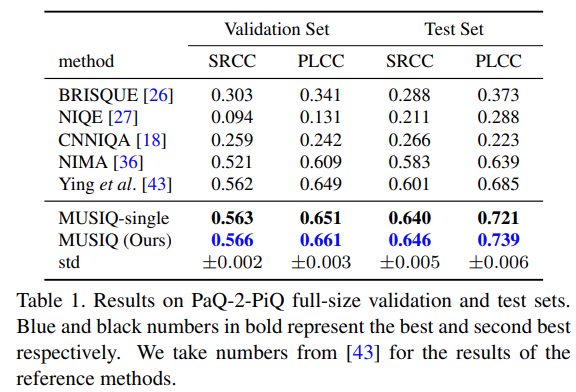
MUSIQ-singleはresizeを行わずにオリジナル画像のみを入力したパターンです。これを見ると、resizeをしなくてもかなりの精度が出ているみたいです。
Ablation study
MUSIQではresizeがIQAに大きな影響を与えるという仮定のもと提案されているので、当然アスペクト比に関する詳細な実験が行われています。まずは、resizeされた画像とオリジナル画像の比較実験で、以下のようにオリジナル画像を使用する方が精度が高いという結果になっています。
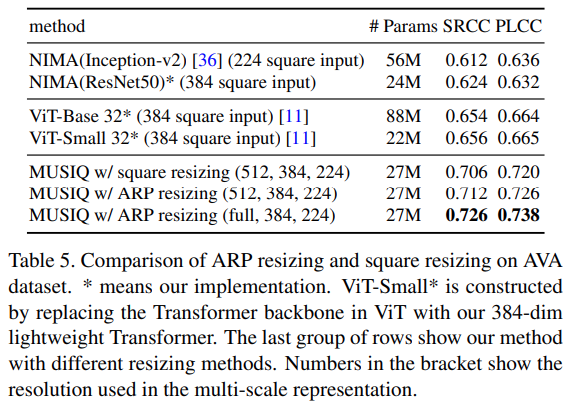
個人的に差はかなり小さいと思いました。自分の推測ですが正方形に近いような画像ではほぼほぼ精度は変わっておらず、極端なアスペクト比画像での精度が高くなっているためにこのような結果になったのではないかなと思います。
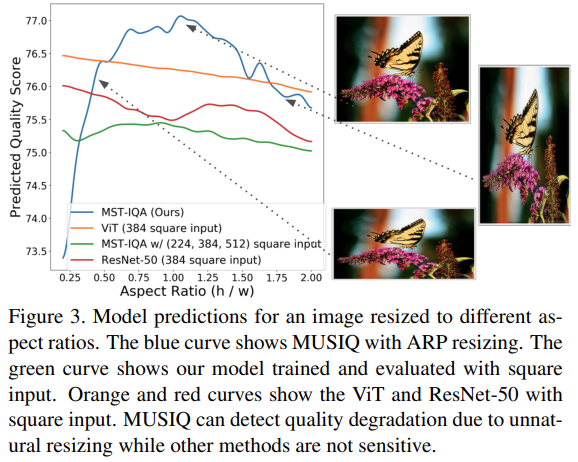
次の実験が個人的にはとても好きです!アスペクト比を変化させてそれぞれのモデルに入力したところ結果がどのようになるかを表示させたもので、MUSIQは元のアスペクト比になるほど推定評価点が高くなっていく傾向が見られるのですが、その他のモデルではあまり大きな変化が見られません。
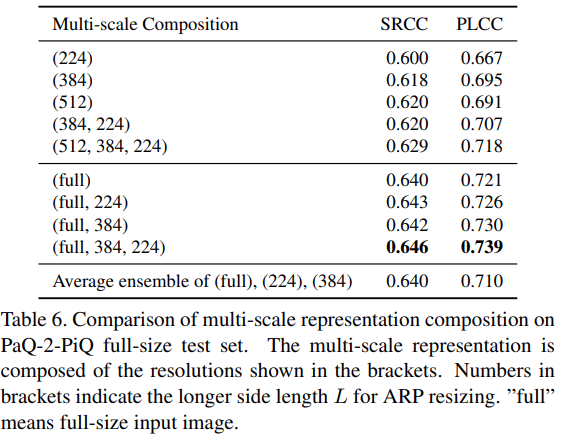
次の実験はresizeの大きさと何回リサイズをするかがどれほど精度に影響をしているかの結果です。これを見ると、オリジナル解像度を扱うことで大きく精度が向上し、それから複数回リサイズを加えることで小さな精度となっていることが分かります。
また、attentionの重みを可視化してみると、論文の説明通り細かいパッチでは局所的な特徴が、大雑把なパッチでは大域的な特徴がattentionされていることが分かります。

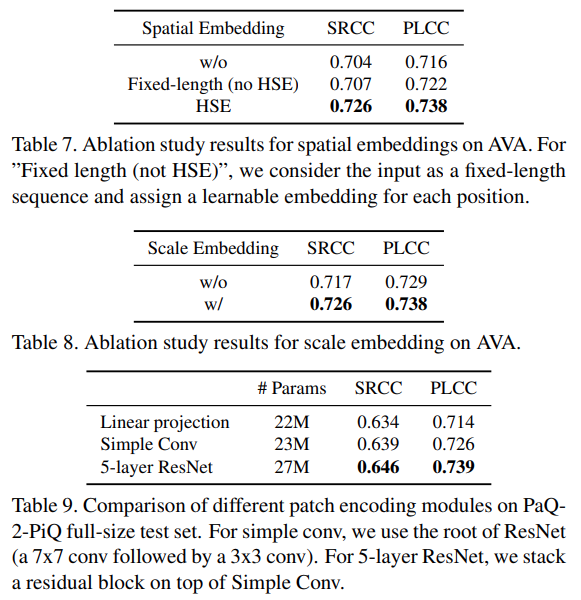
最後の実験は提案しているpositional enbedding層のHSEとSCE、そしてパッチの特徴量抽出機のablation studyをしています。特にtable7ではViTで使われている固定長のpositional embeddingよりもHSEの方が精度が出ていることが確認できます。
おわりに
今回は任意の解像度/アスペクト比の画像をそのまま入力できるTransformer「MUSIQ」の解説をさせて頂きました。MUSIQでは任意の解像度/アスペクト比に対応しマルチスケールな内部表現を得るためにMulti-scale Patch Embeddingというパッチ分割方法と、Hash-based 2D Spatial EmbeddingとScale Embeddingという2つのpositional embedding層を提案しています。評価実験によって4つのIQAデータセットでSoTAとなり、Ablation studiesで各構造による精度変化も調査しています。
ちなみにGithubにとてもきれいなPyTorchの実装が公開されているので参考にどうぞ!
個人的な感想など
まず、IQAというタスクに関してなのですが、最近は旅行に行きガンガン写真を取ると沢山の画像が保存されていて後から選別したりするのが大変だったり、連写で沢山撮り、いい写真を後で選ぶなんて機能もあるので、実現されたらうれしいとても身近なタスクなんだな~と感じました。
CVは最近になって少しづつ勉強を始めたのですが、CNN/ViT共に入力サイズは固定なんだからresizeは必須と勝手に思っていたこともあり、このオリジナル解像度を扱えるMUSIQにはとても驚きました。論文をよく見るとアイデア/構造共にとてもシンプルかつ効果的でとても面白かったです。
手法自体は様々なタスク/構造に応用できるものですので、何かしらに活かせていければと思ってます!
告知
TC3では、Gigコミュニティとの革新的なコラボレーションでDataScience/AI分野での社会実装をより進めていくAIエンジニアを大募集しています!TC3の話が聞きたい、ちょっと興味がある、社内の文化や雰囲気が知りたいという方は@mumeco_mlまでご連絡頂ければご相談に乗れますし、お店でお肉でも食べながらカジュアルにご紹介も可能でございます!


